
「データ基盤構築」と言っても馴染のない方が多いと思いますが、これだけWEBツールやデジタルツールが増えてきた昨今では「複数ある社内のクラウド(WEB)ツールをシームレス(境界性がない)状態で連携して、ツール経費の低コスト化、成果最大化、作業時間短縮に繋げていく」という考え方は不可欠になりつつあります。
ちょっと長い説明になってしまいましたが、端的に言うと「身の周りのあらゆる物事はデータ化できて、そのデータをうまく活用することで目的や結果をより良いものにできる」ということになります。
今回はそれについて掘り下げて、小規模なWEBデータ基盤構築の詳細と一般的な構築手順、メリットなどをお伝えしていきます。
身の周りにあるデータの必要性
データは、個人、法人問わず日常生活や事業を営んでいれば必ず何かしら発生するものです。例えば、ウェブサイトのアクセスログは、ユーザーの行動や関心を示す貴重な情報です。
メールの履歴や問い合わせデータも、顧客のニーズやトレンドを分析するための素材になります。
また、SNSの投稿やレビューサイトのコメントは、リアルタイムで市場の声を捉えるデータ源です。

・WEBサイトへの集客を強化したい→Google広告を配信したら、その「広告費」「申込数(CV)」のデータが日々発生する
・ダイエットしようと思って、毎日の体重をExcelに記入した→データを週別、月別に集計しなおして、体重の変動を把握する
・ダイエットしようと思って、毎日の体重をExcelに記入した→データを週別、月別に集計しなおして、体重の変動を把握する

しかし逆に日々整理して集計、分析の流れを確立できれば、少なくともデータを活用していない時と比べて良い結果が得られる可能性は高いです。
つまり、データ自体に価値があると言えることになります。
そのために身の周りの重要なデータを保存、活用するためのデータ基盤を構築することが有効策となり、
・身の周りにある自社データをより有効に活用することが可能
・全社員の作業時間の短縮や今まで使っていた有料ツールのコンパクト化
・利益もしくは費用対効果(ROAS)の最大化
・全社員の作業時間の短縮や今まで使っていた有料ツールのコンパクト化
・利益もしくは費用対効果(ROAS)の最大化
WEBデータ基盤構築とは
データ基盤の構築は、データの「収集」「蓄積」「加工」「可視化・分析」を一貫して行うことができる仕組みを作ることを指します。弊社が「WEBデータ基盤構築」と呼ぶのは、「WEB周りのマーケティング」に特化した数値ダッシュボードのことです。
ほとんどの事業ではマーケティング活動を営んでいて、何割かはWEBサイトやオンライン経由の売上が占めていますが、PDCAを回して改善に繋げていくためにはWEB上のデータを見て判断する必要があります。
そこで、WEB上のデータを1箇所に集めてしっかりした基盤を構築して、企業のWEBマーケティング活動に活かしていこうという考えです。
実際に、WEB周りのデータをほとんど見ていない、もしくはExcelで表を作って集計するのに時間をかけて簡単な分析しかしていなかった企業が、WEBデータ基盤構築を構築して弊社がアドバイスしながらその後の活用も図っていったことで、利益が2倍、3倍に増えていった事例が多数あります。
複数のデジタルツールを流れに沿って順番に連携するのがポイントですが、良くあるフロー図の事例を下記に図示しました。
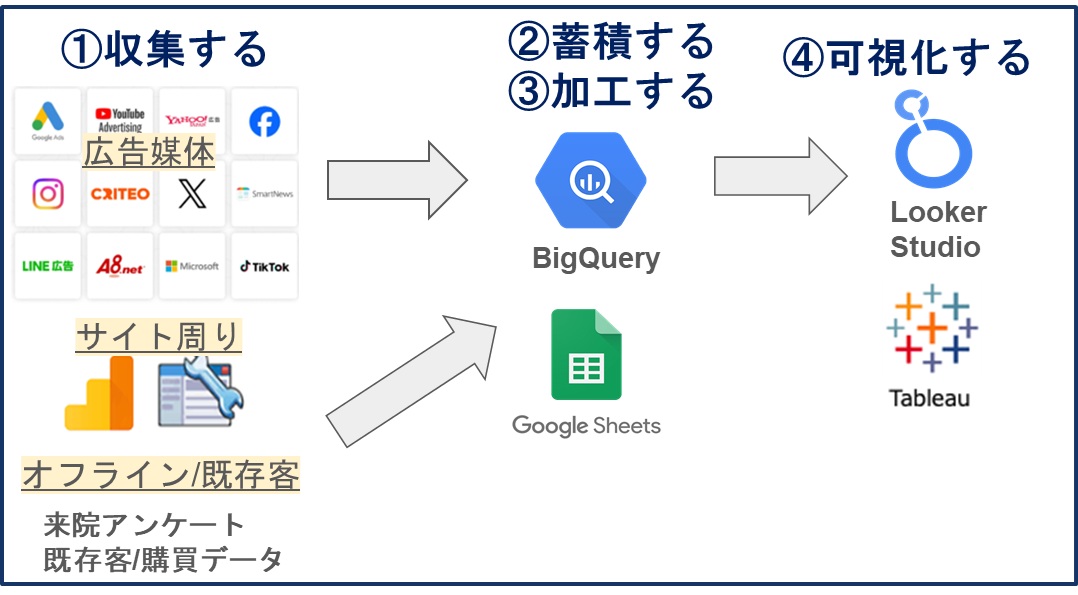
Webデータ基盤構築のステップ
データ基盤を構築するには、目的の明確化、推進チームの立ち上げ、基盤の設計、構築、運用と改善のステップがあります。また、クラウドベースのサービス(例:Amazonが提供するAWS、Googleが提供するGCP)を利用することで、データ基盤の構築が容易になります。
それぞれのステップについて、見ていきます。

1. 目的、課題を明確にする
まずWebデータ基盤を構築する最初のステップは、その目的を明確にすることから始まります。例えば、広告運用データの統合と一元化は重要な課題となっています。
過去の広告運用においては、Google広告であればGoogle広告だけのデータなど個別媒体でのデータ集計が主流でしたが、最近はシームレスな連携と一元管理が求められています。
このようなデータの統合によって、顧客行動の全体像を把握することが可能となります。
また、多くの企業にとってのデータ管理の問題点としては、複数ツールによるデータ収集の大変さが挙げられます。
その他にも、手動でのExcel作業による時間的損失や、データ分析スキルの個人差による業務効率の低下も大きな課題となっています。
これらの課題を解決するためには、日頃から具体的な問題点を洗い出しておいて明確化する必要があります。
そして、それらを一つにまとめて傾向と対策を洗い出して、そこから解決すべき優先順位を適切に決定していくことが重要です。

2. データ蓄積と基盤づくりの方法を決める
データ基盤づくりの次のステップとして、データ蓄積と基盤づくりの方法を決定する必要があります。この段階では、まず課題解決に向けたデータ集計方法を慎重に検討します。例えば、
・どのようなデータソースから情報を収集するか
・データの更新頻度をどうするか
・またそのデータをどのような形式で保存するか
・データの更新頻度をどうするか
・またそのデータをどのような形式で保存するか
といった具体的な検討が必要となります。

例えば、「どのようなデータを組み合わせることで、どのような示唆が得られるか」
「どのような分析を行うことで、ビジネス上の意思決定に役立つ情報が得られるか」
といった具体的な仮説についてです。
できれば、データ分析の目的と期待される成果も明確にしておくのが望ましいです。
そしてこれらの検討結果をふまえて、望むようなデータ分析環境を入れるためのデータ基盤の構想を組み立てていきます。
データの品質管理やセキュリティ対策といった側面も考慮に入れます。

3. データ収集とツール連携のフロー図を決める
次に、データ収集とツール連携のフロー図を決めます。いかに社内のメンバーが使いやすく、効率的なデータ収集の仕組みを構築するかが重要です。
まず、現在所有している各種マーケティングツールやアナリティクスツールを洗い出して、それらのデータの種類の一覧を把握します。
それらをシームレスに連携する際に、APIを活用する場合が多いのでどこで取得できるか確認しておきます。
あとで手作業によるデータ収集の手間を削減することが議題にあがってくるので、手段としてAPIを利用することになります。
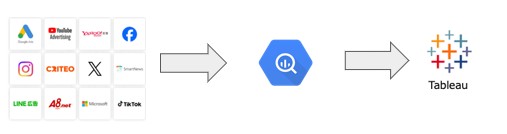
これらのサービスは大量のデータを効率的に保存、処理できて、それぞれ特徴が異なるので自社に合ったツールを選びましょう。 そして、収集するデータの種類と出力形式を決定します。
例えば、ユーザーの行動データ、コンバージョンデータ、広告運用データなど、必要なデータの種類を確認して、それぞれのデータをどのような形式で保存・出力するかを考えます。

そのうえで詳細の各ポイントは要件や既存のシステム環境によって異なる可能性があるため、個々の状況に応じた柔軟な検討が必要です。
4. データの加工と可視化をする
データ基盤構築の次の段階では、収集したデータの加工と可視化を行います。ここでは、生データを意味のある情報へと変換し、関係者が理解しやすい形で提示することが目的です。
SQLの活用やBIツールを用いたデータ整形は、効率的なデータ処理を実現するために検討することになるでしょう。
SQLを使用することで、複数のデータソースから必要な情報を抽出し、結合や集計などの処理を行えます。
また、多くのBIツールは直感的なインターフェースを通じてデータの加工や分析を行える機能を提供しており、技術的な専門知識がない担当者でもデータ処理ができる環境を整えられます。
指標の統一と名称の標準化も重要です。
異なるツールで同じような指標が異なる名称で呼ばれている場合、それらを統一することでデータの解釈における混乱を防ぎます。
また、指標の計算方法を標準化することで、部門間やプロジェクト間での比較分析がより正確に行えます。
グラフや表による効果的な可視化は、データから得られる洞察を共有する上で重要な役割を果たします。
折れ線グラフ、棒グラフ、散布図など、データの性質や伝えたいメッセージに応じて適切な可視化方法を選択します。
また、ダッシュボードを作成することで、重要な指標をリアルタイムでモニタリングできる環境を構築できます。
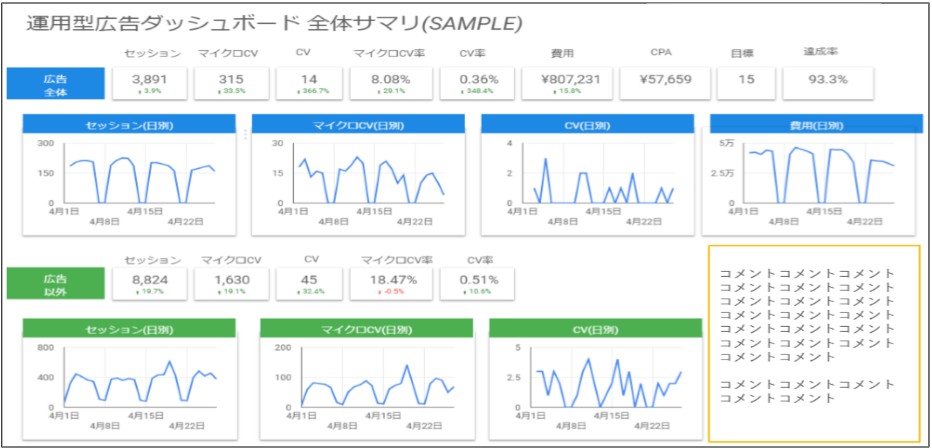
5. データの共有と活用を行う
ここまで来たらあとはデータを共有する範囲を決めます。・社内だけで全メンバーに共有する
・社外の関係者にダッシュボードの全ページを共有する
・関係者ごとに共有するダッシュボードの範囲を調整する
・社外の関係者にダッシュボードの全ページを共有する
・関係者ごとに共有するダッシュボードの範囲を調整する
データの内容に応じて柔軟に権限を変えることができるので、詳しいメンバーがセキュリティ面に注意しながら設定していきましょう。
データ種類の事例
次に構築したWEBデータ基盤で、良くある事例を下記に記載します。例1)異なる広告媒体データの統合
Google広告やYahoo!広告などの主要プラットフォームでは、それぞれ独自のフォーマットでデータが提供されており、Looker Studioなど統合したデータを可視化することができます。
これによって、インプレッション数、クリック数、コンバージョン数などの主要指標を統一化してデータ出力することができます。
また、キャンペーン別やキーワード別の詳細なレポートを作成することで、より細かな施策の効果測定が実現できます。
例えば、特定のキャンペーンにおけるキーワードごとの投資対効果(ROAS)を算出したり、時系列での推移を追跡したりできます。

他にもスマートフォン、タブレット、PCなど、デバイスごとのデータを定期的に更新して、それぞれの違いを数値で見ながら状況に合わせて最適な改善に活かすこともできます。
例2)サイト内行動データの活用
サイト内でのユーザー行動を正確に把握し、そのデータを適切に活用することが重要です。Google Analytics 4(GA4)のコードを設定して、より詳細なユーザー行動の分析をすることが一般的です。
GA4とのデータ計測は、旧ツールの「ページビュー」中心の計測から、「イベント」主体の柔軟な計測へと変わっています。
この違いを確認しながら目的に合わせたデータを収集・分析する必要があります。
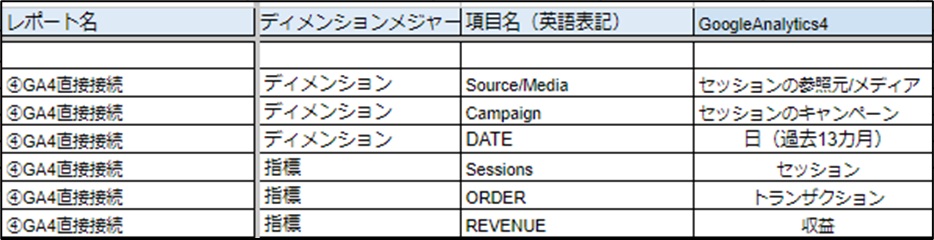
・セッション
・トランザクション
・ページスクロール
・フォーム入力の完了率
・ボタンクリック
・ユーザーの滞在時間
・トランザクション
・ページスクロール
・フォーム入力の完了率
・ボタンクリック
・ユーザーの滞在時間
これらのデータをデータウェアハウスと連携させることで、より広範囲に分析基盤を構築することができます。
広告流入からコンバージョンまでの計測では、GA4のクロスプラットフォーム分析機能を活用します。
ユーザーが広告をクリックしてサイトに訪問してから、最終的なコンバージョンに至るまでの一連のジャーニーを追跡することが可能です。
例えば、以下のような指標を分析します。
・ランディングページでの直帰率
・コンバージョンまでの平均ステップ数
・離脱が多発するページの特定
・コンバージョンまでの平均所要時間
・各タッチポイントでの離脱率
・コンバージョンまでの平均ステップ数
・離脱が多発するページの特定
・コンバージョンまでの平均所要時間
・各タッチポイントでの離脱率
これらのデータを統合的に分析することで、以下のような施策の最適化が可能となります。
・ランディングページの改善点の特定
・コンバージョンまでの導線の最適化
・ユーザー離脱ポイントの改善
・コンテンツの最適な配置
・コンバージョンまでの導線の最適化
・ユーザー離脱ポイントの改善
・コンテンツの最適な配置
また、サイト内のデータをGA4単独で見るのではなく、広告データと組み合わせて分析することも増えてきています。
例えば、特定の広告キャンペーンからの流入がどのような行動パターンを示すのか、どの導線が最も効率的にコンバージョンを生み出しているのかなどです。
このように複数のツールをシームレスに分析することを求められている場合もあるので、社内だけで完結しなければ外部の経験豊富な会社に依頼することも1つの選択肢となりそうです。
例3)既存顧客データの活用
既存顧客のデータ活用は新規顧客獲得と比較して、利益率やLTVを改善する対策に直結する施策を実施できるので、企業でも注目されています。。例えば会員登録済みやサンプル体験済みの顧客はすでにサービスへの理解があるので、より深い関係構築ができる重要なセグメントです。
細分化すると、下記の要素や指標をKPIとして数値を追うことが良くあります。
・顧客プロフィールの統合
・会員登録情報
・購買履歴
・サービス利用頻度
・問い合わせ履歴
・メールマガジン開封率
・サンプル体験時のフィードバック
・行動データの収集と分析
・サイト内での回遊パターン
・商品閲覧履歴
・カート放棄情報
・お気に入り登録状況
・クーポン利用履歴
・会員登録情報
・購買履歴
・サービス利用頻度
・問い合わせ履歴
・メールマガジン開封率
・サンプル体験時のフィードバック
・行動データの収集と分析
・サイト内での回遊パターン
・商品閲覧履歴
・カート放棄情報
・お気に入り登録状況
・クーポン利用履歴
これらのデータを統合的に活用することで、優良客も含まれる既存顧客に対して1人1人に近い粒度で対策を行うことができます。
例えば、次のような施策です。
・リピート購入を促進するためのタイミングに合わせた商品レコメンデーション
・過去の購買パターンに基づいた適切な価格帯の商品提案
・利用頻度に応じたロイヤリティプログラムの最適化
・商品カテゴリーごとの購買サイクルを考慮したプロモーション展開
・過去の購買パターンに基づいた適切な価格帯の商品提案
・利用頻度に応じたロイヤリティプログラムの最適化
・商品カテゴリーごとの購買サイクルを考慮したプロモーション展開
またサンプル体験済みの顧客に対しては、体験時のフィードバックデータを活用して下記のアプローチを行うことが考えられます。
・体験評価が高かった商品
・サービスの優先的な案内
・体験時の課題点を解決した新商品のご案内
・体験後一定期間経過した顧客への再アプローチ
・類似商品のクロスセル提案
・サービスの優先的な案内
・体験時の課題点を解決した新商品のご案内
・体験後一定期間経過した顧客への再アプローチ
・類似商品のクロスセル提案
また既存顧客のデータを活用する際は、以下の点に留意することが重要です。
・プライバシーポリシーの遵守
・データの鮮度維持
・適切なコミュニケーション頻度の設定
・セグメントに応じた最適なチャネルの選択
・データの鮮度維持
・適切なコミュニケーション頻度の設定
・セグメントに応じた最適なチャネルの選択
データ基盤構築によるメリット
次にデータ基盤を構築することによるメリットについてです。業務効率の向上
繰り返しになりますが、データ基盤の構築は組織の業務効率を上げてくれて、より重要な業務に集中することができます。データ集計時間の大幅削減は、データ基盤構築による最も顕著な効果の一つです。
これまで多くの企業が、複数のシステムやプラットフォームからデータを手動で抽出し、Excelなどのツールを使用して加工・集計する作業に膨大な時間を費やしてきました。
しかし、データ基盤を構築することで、これらの作業を自動化し、数時間かかっていた作業を数分で完了させることも可能です。
また、手作業による入力ミスやフォーマットがバラバラといった問題も解消されます。
自動更新によるリアルタイムデータ分析の実現は、ビジネスの意思決定スピードを速くします。
データ基盤によって、販売データ、顧客行動データ、広告効果データなどが自動的に更新されれば、常に最新の情報に基づいた分析ができるようになります。
そうすれば、マーケティングの各キャンペーンの効果をリアルタイムで把握して、迅速なPDCAを行うことができます。
また在庫管理や需要予測においても、リアルタイムデータを活用することでより適切な判断ができるようになります。
エラー発見と修正の迅速化も、業務効率向上における重要な要素です。
データ基盤には、データの異常値や不整合を自動的に検出する機能を組み込むことができます。
これにより、従来は気づくまでに時間がかかっていたエラーを早期に発見し、対処することが可能となります。
また、エラーの原因特定も容易になり、再発防止のための対策を迅速に実施することができます。
システム内でのデータの流れが可視化されることで、問題が発生した箇所を特定しやすくなり、修正作業の効率も大きく向上します。
これらの改善は、単なる作業時間の短縮にとどまらず、組織全体の生産性向上につながります。
自動化された正確なデータ処理により、従業員はより創造的な業務や戦略的な判断に時間を充てることができます。
また、部門間でのデータ共有がスムーズになることで、組織全体のコミュニケーションも改善され、より効率的な協業が可能となります。
さらに、データ基盤の構築は、業務プロセスの標準化と改善にも貢献します。
データの収集から分析、レポーティングまでの一連のプロセスが統一され、属人的な作業が減少することで、業務の質の向上と安定化が図れます。
これにより、新入社員の教育や引継ぎも効率化され、組織全体の生産性向上につながります。
意思決定の質の向上
データ基盤の構築は、組織における意思決定プロセスを根本的に変革し、より精度の高い判断ができるようになります。これまで経験や勘に頼っていた判断を、客観的なデータに基づいた意思決定ができるようになります。
データに基づく客観的な判断材料の提供により、市場動向や顧客行動の把握がより正確になります。
例えば、売上データと顧客行動データを組み合わせることで、特定の施策がどの程度の効果をもたらしたのか、そしてその効果がどのような顧客層に強く表れているのかを具体的に把握することができます。
また、時系列データの分析により、季節変動や市場トレンドをより正確に予測することも可能となり、先手を打った施策の実施が可能になります。
経営層への適切な情報提供という観点では、データ基盤の構築により、必要な情報をリアルタイムで提供することが可能となります。
経営判断に必要な重要指標を、ダッシュボードを通じて一元的に把握できるようになり、状況の変化にも迅速に対応することができます。
また、データの可視化により、複雑な情報も直感的に理解しやすい形で提供することが可能となり、より迅速な意思決定をサポートします。
運用改善のための具体的な指標の可視化においては、現場レベルでの改善活動をより効果的に推進することができます。
例えば、マーケティング施策においては、広告の費用対効果や顧客獲得コスト、顧客生涯価値などの指標をリアルタイムで把握することが可能となります。
これにより、施策の効果を迅速に評価し、必要な改善を行うことができます。
また、ユーザー行動の詳細な分析により、サービスの問題点や改善機会を具体的に特定することも可能となります。
このようなデータ駆動の意思決定プロセスは、組織全体の効率性と効果性を高めます。
具体的な数値に基づく判断により、リソースの最適配分が可能となり、投資効率の向上にもつながります。
また、データに基づく客観的な評価により、組織内でのコミュニケーションも改善され、より建設的な議論が可能となります。
さらに、継続的なデータ分析により、中長期的な戦略立案もより精度の高いものとなります。
市場動向や顧客ニーズの変化を早期に察知し、それに応じた戦略の修正を行うことで、競争優位性を維持・向上させることができます。
このように、データ基盤の構築は、組織の意思決定プロセスを質的に向上させ、持続的な成長を支える重要な基盤となります。
データの正確性と一貫性の確保
データ基盤構築において、データの正確性と一貫性も重要な要素です。信頼性の高いデータ基盤を構築し維持するためには、一貫性かつ体系的なアプローチが必要です。
複数のシステムやプラットフォームから収集されるデータは、それぞれ異なるフォーマットや単位、更新タイミングを持っていることが一般的です。
例えば、売上データと顧客データを統合する際には、日付形式の統一や通貨単位の標準化、重複データの適切な処理が必要です。
また、データの欠損や異常値の検出も重要な確認ポイントです。
定期的に整合性のチェックを実施することが、関係者に対してデータの信頼を維持することに繋がります。
そのためには、データの完全性、正確性、最新性などを定期的にチェックし、問題が見つかった場合には速やかに修正を行う必要があります。
また、これらの取り組みは、一度実施すれば終わりというものではなく、継続的な改善と更新が必要です。
テクノロジーの進化や業務要件の変化に応じて、データ品質管理の方法も進化させていく必要があります。
また、データ品質の維持向上は、技術的な側面だけでなく、組織文化としてデータ品質を重視する姿勢を育むことも重要です。
セキュリティとプライバシーの考慮
最後にデータ基盤のセキュリティとプライバシー保護も、最重要課題の一つです。組織が保有する重要なデータを適切に保護し、安全に活用するためにはセキュリティ対策とプライバシー保護が不可欠です。
データにアクセスする権限は、できるだけ最小限にしましょう。
業務担当者の中で編集しないメンバーには閲覧権限のみを付与し、データの編集や削除といった操作を行うなら編集権限、メンバーの追加、削除まで行うなら管理者のみが実行できるような制限を設けます。
また、プロジェクトや部門ごとにアクセス可能なデータを制限することで、情報漏洩のリスクを最小限に抑えることができます。
そして、定期的な権限の見直しや退職者のアクセス権限の速やかな削除など、継続的な管理も重要となります。
上記とは別に顧客の個人情報を扱う場合は、個人情報保護法に準拠したデータ管理に基づいて法令の要件を満たすだけでなく、個人のプライバシーを適切に保護することが求められます。
収集した個人情報は、利用目的の範囲内でのみ使用し、不必要なデータは適切に削除する仕組みを整えることが重要です。
特に作成だけ外部の業者に依頼する場合は、契約条項で入念な合意形成や取り交わしが発生するので、できる限り他社の面前に触れさせない想定で進めるほうが良いです。
また、個人情報の取り扱いに関する社内規程の整備 や、従業員への教育・研修 も欠かせません。
特に注意が必要なのは、データの越境移転や第三者提供に関する規制への対応です。
クラウドサービスの利用やグローバルな事業展開において、データの保管場所や移転先の法規制にも注意を払う必要があります。
その時にも取引先やパートナー企業とのデータ共有においても、適切な契約や合意を結び、セキュリティレベルを確保することが重要です。
データ漏洩や不正アクセスのリスクに対しては、技術的な対策も重要です。
暗号化技術の活用、アクセスログの記録と監視、定期的なセキュリティ診断の実施など、複数の防衛層を設けることで、セキュリティレベルを高めることができます。
そしてインシデント発生時の対応手順を事前に整備して、万が一の事態にも迅速に対応できる体制を整えるおく必要があります。
これらのセキュリティとプライバシー対策は、組織全体で取り組むべき継続的な活動として位置づける必要があります。
技術の進歩や法規制の変更に応じて、常に対策を見直し、改善を図ることが重要です。
また、セキュリティ意識の向上を図るための従業員教育や、定期的な監査の実施など、組織文化としてセキュリティとプライバシー保護を重視する姿勢を育むことも必要です。
このように、データ基盤のセキュリティとプライバシー保護は、技術的な対策だけでなく、組織的な取り組みと継続的な改善が求められる重要な課題です。
適切な対策を講じることで、組織の信頼性を高め、持続可能なデータ活用を実現することができます。
■関連記事
労務管理システムの導入のメリットと自社に合ったシステムの選び方を解説 | SES業務管理の統合ツール Fairgrit®公式サイト

